Projects in Depictio¶
Projects are the foundation of data organization in Depictio. They serve as containers for your data and dashboards, providing structure and access control for your analysis.
🎬 Projects Management Overview: Discover how Depictio's project types organize your data workflow
Understanding Project Architecture¶
Every Depictio project contains:
- Core Project Information - Name, description, and metadata
- Data Organization - Either direct data collections (Basic) or workflow-based structure (Advanced)
- Permission System - Role-based access control with owners, editors, and viewers
- Dashboard Integration - Each dashboard is linked to a project, allowing for interactive data exploration
- Storage Backend - Automatic conversion to Delta Lake format for optimal performance
Project Lifecycle¶
graph TD
A[Create Project] --> B{Project Type?}
B -->|Basic| C1[Create Data Collection]
C1 --> C2[Upload Data Files]
C2 --> D[Data Processing]
B -->|Advanced| D1[Define Project Config]
D1 --> D2[Configure Workflows]
D2 --> D2a{For each Workflow}
D2a --> D3[Define 1 or Multiple<br/>Data Collections]
D3 --> D2a
D2a -->|All Workflows<br/>Configured| D4[Run CLI Validation]
D4 --> D5[File Discovery & Scanning]
D5 --> D
D --> E[Create Dashboards :material-view-dashboard:]
E --> F[Share & Collaborate]
%% Depictio teal theme styling - compatible with light/dark mode
classDef default fill:#45B8AC,stroke:#2E7D73,stroke-width:2px,color:#fff
classDef decision fill:#5FCBC4,stroke:#45B8AC,stroke-width:2px,color:#fff
classDef highlight fill:#2E7D73,stroke:#45B8AC,stroke-width:2px,color:#fff
class A,D,E,F highlight
class B,D2a decisionBasic Projects¶
Perfect for: Direct data analysis and quick insights
Use when: You have tabular data files ready for analysis and want immediate visualization capabilities.
Basic projects provide an easy onboarding experience - upload your data and start creating interactive dashboards within minutes.
🎬 Basic Project Creation: Watch how to create a basic project from scratch - upload data and start visualizing in minutes
Core Features¶
- 🚀 Immediate Setup - No configuration files needed
- 📁 Direct File Upload from WebUI - Drag and drop your data files
- 🔄 Flexible Data Formats - CSV, Excel, Parquet, Feather
- ⚡ Fast Processing - Direct conversion to Delta Lake format
- Instant Visualization - Start creating dashboards immediately
Supported File Formats¶
| Format | Extension | Best Use Case |
|---|---|---|
| CSV | .csv |
Most common, universal compatibility |
| TSV | .tsv |
Tab-separated, good for scientific data |
| Excel | .xlsx, .xls |
Business data, multiple sheets |
| Parquet | .parquet |
Large datasets, optimal performance |
| Feather | .feather |
Fast I/O, preserves data types |
Creating a Basic Project¶
- Navigate to Projects - Click "Projects" in the main navigation
- Create Project - Click the "Create Project" button
- Choose Basic Type - Select "Basic Project" from the options
- Project Details - Fill in name and description
- Project data management - Navigate to the "Data Collections" tab
- Upload Data - Add your data files to collections by creating a new collection
- Click "Add Data Collection"
- Drag and drop files or use the file picker
- Supported formats: CSV, TSV, Excel, Parquet, Feather
- Start Visualizing - Create dashboards with your data
- Create Configuration File - Write a YAML file defining your project
# Create a basic project configuration file - basic_project.yaml
name: "My Basic Project"
project_type: "basic"
data_collections:
- data_collection_tag: "my_data"
config:
type: "Table"
metatype: "Metadata"
scan:
mode: "single"
scan_parameters:
filename: "/path/to/data.csv"
dc_specific_properties:
format: "CSV"
polars_kwargs:
separator: ","
has_header: true
- Run CLI Command - Use the Depictio CLI to create the project
Advanced Projects¶
Perfect for: Bioinformatics workflows and complex data pipelines
Use when: You have automated pipelines generating data with standardized file organization and need to process multiple samples systematically.
Advanced projects are designed for core facility-like setups where standardized workflows generate structured data across multiple samples, timepoints, or experimental conditions.
Core Features¶
- 🔬 Workflow Integration - Connect to nf-core, Nextflow, Snakemake, Galaxy pipelines
- 📊 Multi-sample Analysis - Handle large number of samples
- 🔍 File Discovery - Regex-based pattern matching for file organization
- 🔗 Cross-DC Links - Interactive filtering across data collections (tables, MultiQC, etc.)
- 📈 Scalable Processing - Delta Lake backend for large-scale data
Project Structure Example¶
study_directory/
├── depictio_project.yaml # Configuration file
├── run_001/ # First sample batch
│ ├── sample_A/
│ │ ├── stats/
│ │ │ └── sample_A_stats.tsv
│ │ └── analysis_results/
│ │ └── sample_A_analysis.tsv
│ └── sample_B/
│ ├── stats/
│ │ └── sample_B_stats.tsv
│ └── analysis_results/
│ └── sample_B_analysis.tsv
└── run_002/ # Second sample batch
├── sample_C/
│ ├── stats/
│ │ └── sample_C_stats.tsv
│ └── analysis_results/
│ └── sample_C_analysis.tsv
└── sample_D/
├── stats/
│ └── sample_D_stats.tsv
└── analysis_results/
└── sample_D_analysis.tsv
Configuration File Format¶
Advanced projects require a YAML configuration that describes data organization patterns:
# =============================================================================
# DEPICTIO ADVANCED PROJECT CONFIGURATION
# =============================================================================
# Project identification
name: "RNA-seq Expression Study"
project_type: "advanced"
description: "Multi-sample RNA sequencing analysis"
is_public: false
# Workflow definition
workflows:
- name: "rnaseq_pipeline"
# Workflow engine information
engine:
name: "nextflow" # or "snakemake", "python"
version: "24.10.3"
description: "nf-core RNA-seq analysis pipeline"
repository_url: "https://github.com/my-org/my-nf-wf-rnaseq"
# Data organization configuration
config:
# Data location settings
parent_runs_location:
- "{DATA_LOCATION}/rnaseq-results" # Environment variable
- "/absolute/path/to/data" # Alternative absolute path
# Run identification pattern
runs_regex: ".*" # Matches all directories
# Data collections definition
data_collections:
# Sample statistics collection
- data_collection_tag: "sample_stats"
description: "Per-sample quality control statistics"
config:
type: "Table"
metatype: "Aggregate" # Combine multiple files
# File discovery settings
scan:
mode: "recursive"
scan_parameters:
regex_config:
pattern: "stats/.*_stats.tsv"
# Processing configuration
dc_specific_properties:
format: "TSV"
polars_kwargs:
separator: "\t"
has_header: true
# Column selection for performance
keep_columns:
- "sample_id"
- "total_reads"
- "mapped_reads"
- "quality_score"
# Human-readable descriptions
columns_description:
sample_id: "Unique sample identifier"
total_reads: "Total sequencing reads"
mapped_reads: "Successfully aligned reads"
quality_score: "Overall sample quality metric"
# Analysis results collection
- data_collection_tag: "gene_expression"
description: "Gene expression analysis results"
config:
type: "Table"
metatype: "Aggregate"
scan:
mode: "recursive"
scan_parameters:
regex_config:
pattern: "analysis_results/.*_analysis.tsv"
dc_specific_properties:
format: "TSV"
polars_kwargs:
separator: "\t"
has_header: true
keep_columns:
- "sample_id"
- "gene_id"
- "expression_level"
- "p_value"
# Cross-DC Links: Interactive filtering between data collections
links:
- source_dc_id: "sample_stats" # Filter from this DC
source_column: "sample_id" # Filter by this column
target_dc_id: "gene_expression" # Update this DC
target_type: "table" # Target type: table or multiqc
link_config:
resolver: "direct" # Same value in both DCs
File Discovery Patterns¶
Advanced projects use two scanning modes:
Single File Mode¶
Perfect for metadata files or summary statistics generated once per project:
Recursive Mode¶
Uses regex patterns to find files at any directory depth:
CLI Workflow¶
Process advanced projects using the CLI:
The CLI executes this pipeline:
- ✅ Server Check - Verify connection to Depictio backend
- ✅ S3 Storage Check - Validate cloud storage configuration
- ✅ Config Validation - Ensure YAML structure is correct
- ✅ Config Sync - Register project with server
- ✅ File Scan - Discover files matching patterns
- ✅ Data Process - Convert files to Delta Lake format
Managing Data Collections from the viewer (v0.12.0+)¶
Data Collections can be created and managed directly from the viewer — no YAML edits or CLI runs required. Available for Basic projects today; some flows also work on Advanced projects.
Available from v0.12.0
All flows in this section require Depictio v0.12.0 or later. See the changelog for the full release notes.
MultiQC Data Collections¶
MultiQC DCs support a full lifecycle from the Manage Data Collection modal:
| Action | What it does |
|---|---|
| Create | Upload one or more MultiQC reports (single file or folder) — the DC is materialised with cache prewarmed via Celery |
| Append | Add more runs to an existing DC; the live cache is invalidated and rewarmed |
| Replace | Swap the underlying report set in place |
| Clear | Drop all data from the DC while keeping the definition |
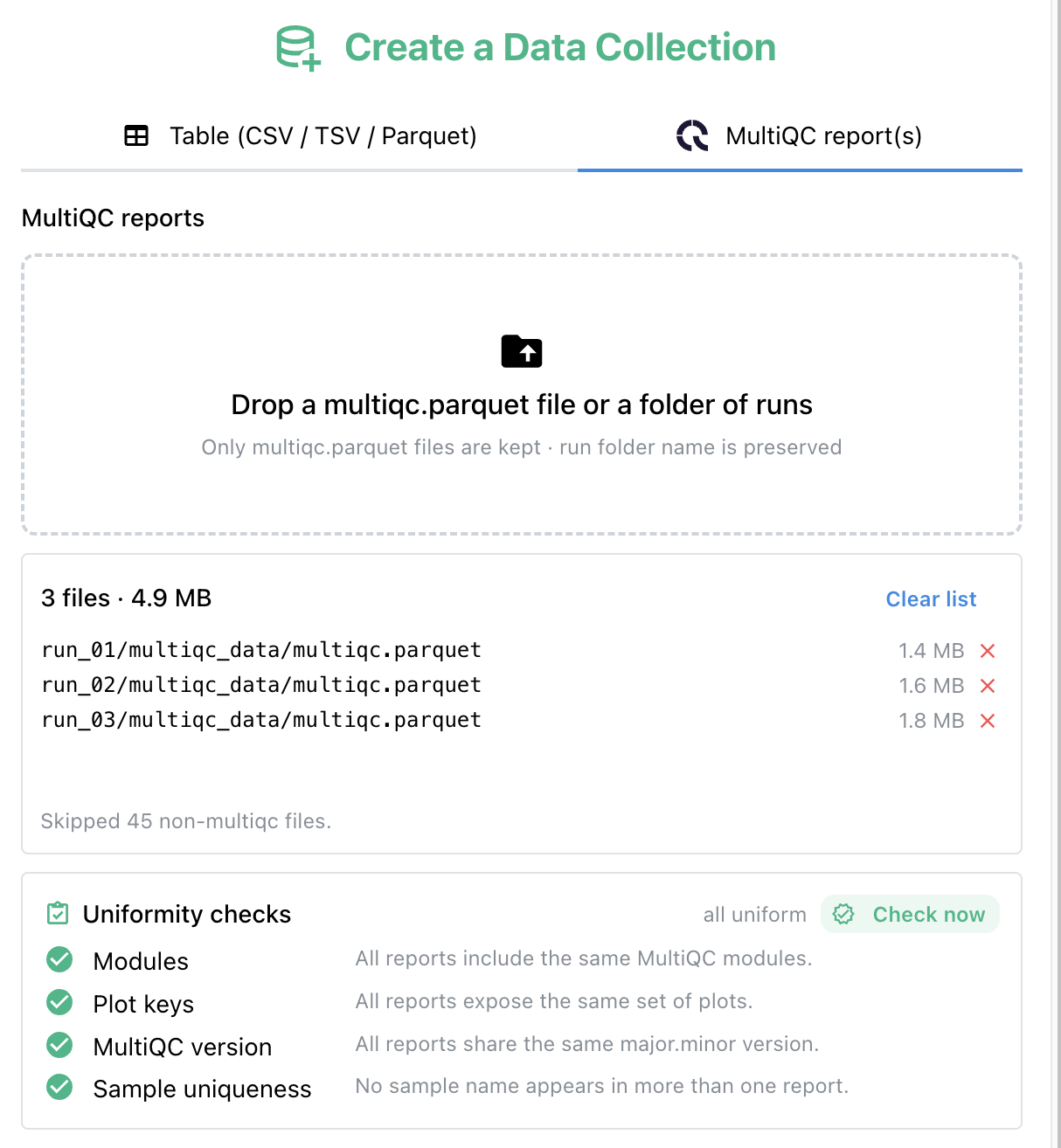
Uniformity validation (React Beta)¶
Web interface
The uniformity checklist UI and the Check now button are available in the web interface. The validator endpoint can be called from any client.
Before ingest, MultiQC reports are checked for uniformity — the same module set and column schema across runs — so plot rendering stays consistent. The check runs automatically on Create and on every Append, and can be re-run on demand with the Check now button.
Non-uniform reports surface a checklist of differences (missing modules, divergent columns) and block the destructive action until resolved.
Type-specific Data Collection configuration (React Beta)¶
Web interface
The UI for type-specific DC configuration is available in the web interface. YAML-level configuration is supported everywhere.
Some visualization types need extra metadata declared at the Data Collection level (e.g. which columns hold coordinates, which hold sample IDs, log-fold-change, p-values, …). Declaring this on the DC means every figure built on top inherits the config — no need to re-specify it per component.
This pattern is being rolled out incrementally. The first shipped example is Map; advanced-viz types (volcano, ComplexHeatmap, UpSet, GSEA enrichment, rarefaction, …) will follow the same pattern.
Example: Map-capable Table DCs¶
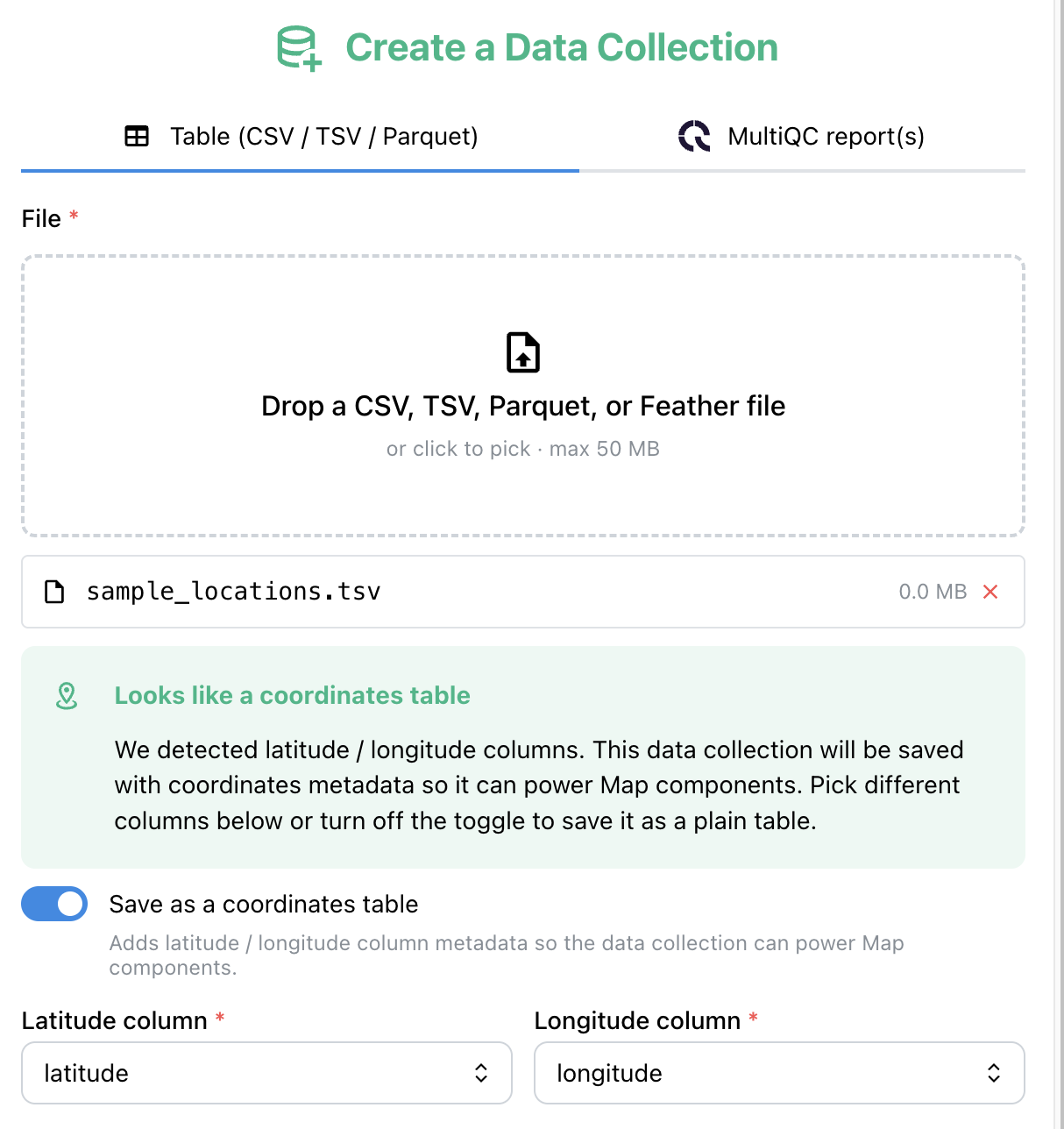
Tabular DCs can be marked Map-capable so every Map figure built on them inherits the same coordinates without re-specifying lat_column / lon_column:
- In the React viewer: the Create DC modal has a Coordinates tab. Columns are scanned and lat/lon candidates are detected inline — you confirm or override the pick.
- At upload time:
POST /create_from_uploadacceptslatColumnandlonColumnquery params with column-existence validation. - In YAML: use
DCTableCoordinatesConfigon the DC's config block (see YAML examples).
Per-figure lat_column/lon_column overrides still work when set; if both are unset, the DC-level config is used.
Template Projects¶
Perfect for: nf-core pipelines and standardized bioinformatics workflows
Use when: You have output from a supported pipeline (e.g. nf-core/ampliseq) and want a fully configured project + dashboards in one command — without writing any YAML.
Templates are pre-packaged project configurations that ship with Depictio. Each template bundles a project YAML (with {DATA_ROOT} placeholders), bundled dashboards, and referenced data transformation recipes for a specific pipeline version.
One-command setup¶
That single command:
- Validates your data directory structure against the template's
expected_files - Resolves all
{DATA_ROOT}placeholders throughout the config - Creates the project in MongoDB
- Discovers and processes all data collections (running recipes automatically)
- Imports the bundled dashboard
When to use templates¶
Use templates when:
- ✅ You ran a supported nf-core pipeline (e.g. ampliseq) and want instant visualization
- ✅ You want a reproducible, versioned project setup you can share with collaborators
- ✅ You prefer not to write project YAML from scratch
Use a manual YAML config when:
- ✅ Your pipeline is not yet covered by a bundled template
- ✅ You need highly customized data collection patterns or scan configurations
- ✅ You want fine-grained control over which files are included
Template workflow diagram¶
graph TD
A(["🚀 <b>depictio run --template X</b>"])
A --> B["📦 Resolve template<br/><i>substitute {DATA_ROOT}</i>"]
B --> C["✅ Validate data dir<br/><i>Level 1 / Level 2 (--deep)</i>"]
C --> D["⚙️ Sync · Scan · Process<br/><i>standard pipeline + recipes</i>"]
D --> E["📊 Import bundled dashboards"]
E --> F(["✨ <b>Project ready</b><br/><i>badge: Template: nf-core/ampliseq/2.16.0</i>"])
classDef default fill:#E0F2F1,stroke:#45B8AC,stroke-width:2px,color:#2E7D73
classDef endpoints fill:#45B8AC,stroke:#F68B33,stroke-width:3px,color:#fff
class A,F endpointsTemplate origin badge¶
Once imported, every dashboard card in the UI shows a badge:
This tells you and your collaborators which template generated the project, enabling template discovery and making provenance visible throughout the UI.
For full template reference — available templates, data validation levels, YAML structure, and all CLI flags — see Templates.
Project Types Comparison¶
Choose the right project type for your workflow:
| Feature | Basic Projects | Advanced Projects | Template Projects |
|---|---|---|---|
| Setup Complexity | Minimal - Web UI or CLI | CLI only today (WebUI planned), YAML config required | Single CLI command, no YAML needed (WebUI planned) |
| Data Sources | UI File upload or CLI-based processing | CLI-based processing | CLI-based (pipeline output) |
| File Organization | Simple file management | Structured directory patterns | Fixed structure per template |
| Multi-sample Support | Single datasets | Multi samples support | Full support (template-specific) |
| Data Processing | Direct conversion | Aggregation & cross-DC links | Recipes + cross-DC links (pre-configured) |
| Learning Curve | Immediate | Moderate (YAML knowledge) | Minimal (just point at data dir) |
| Scalability | Small-medium datasets | Large-scale studies | Pipeline-scale (template-specific) |
How to Choose the Right Project Type¶
Choose Basic when:
- ✅ You have a limited number of files ready for analysis
- ✅ One-time analysis or ad-hoc exploration
- ✅ Manual data preparation is acceptable
- ✅ Quick insights are the primary goal
Choose Advanced when:
- ✅ Automated pipelines generate your data
- ✅ Standardized file organization exists
- ✅ You need to aggregate data across samples/runs
- ✅ Regular data updates are expected
Choose a Template when:
- ✅ You ran a supported nf-core pipeline (e.g. ampliseq)
- ✅ You want instant project + dashboards without writing YAML
- ✅ Reproducibility and template provenance tracking matter
Project Permissions¶
Depictio implements a comprehensive role-based permission system:
Permission Roles¶
| Role | Capabilities |
|---|---|
| Owner | Full control - edit, delete, manage permissions |
| Editor | Modify project data, create/edit dashboards |
| Viewer | Read-only access to project and dashboards |
Public Projects¶
Projects can be made public by:
- Setting
is_public: truein configuration - Using the web interface toggle
Public projects are:
- ✅ Visible to all users
- ✅ Read-only for non-members
- ✅ Searchable in project listings
- ❌ Only editable by owners and editors
- ❌ Not editable by viewers or anonymous users
Project deletion¶
Deleting a project (via the Web UI or DELETE /depictio/api/v1/projects/{id})
cascades to all dependent state:
- Workflows declared in the project
- Data collections (and their MongoDB documents)
- Dashboards owned by the project
- S3 objects under
s3://<bucket>/{project_id}/
There is no soft-delete or trash bin — once the operation completes, the project's data is unrecoverable. Use Project migrate to take a portable backup ZIP before deletion if you need rollback capability.
Self-migration shortcut
Migrating a project to the same instance (source == target) skips the S3 copy step but still produces a complete export ZIP — useful for backing up immediately before a delete.
💾 Data Storage Architecture¶
Delta Lake Backend¶
All project data is automatically converted to Delta Lake format which provides following benefits:
- ACID Transactions - Reliable data consistency
- Time Travel - Version history and rollback capabilities
- Schema Evolution - Handle changing data structures
- Optimized Queries - Fast dashboard performance
- Compression - Efficient storage utilization
Future Depictio versions will support aforementioned features progressively, enhancing user experience and data management capabilities.
Storage Hierarchy¶
Project Storage Structure:
├── metadata/ # Project configuration and metadata
├── data_collections/ # Raw data collections
│ ├── collection_1/
│ │ ├── delta_table/ # Optimized Delta Lake format
│ │ └── metadata.json # Collection-specific metadata
│ └── collection_2/
├── dashboards/ # Dashboard configurations
└── permissions/ # Access control data
Performance Optimizations¶
- Lazy Loading - Load data only when needed
- Column Pruning - Select only required columns
- Predicate Pushdown - Filter data at storage level
- Caching - Cache frequently accessed data
- Partitioning - Optimize queries by partition keys
🔧 Advanced Configuration Options¶
Environment Variables¶
Use environment variables for flexible deployments:
# Configuration with environment variables
parent_runs_location:
- "{DATA_LOCATION}/study1" # Resolved at runtime
- "{BACKUP_LOCATION}/study1" # Alternative location
Polars Integration¶
Advanced data processing with Polars DataFrames:
dc_specific_properties:
format: "CSV"
polars_kwargs:
separator: ","
has_header: true
skip_rows: 1
column_types:
sample_id: "String"
expression: "Float64"
p_value: "Float64"
null_values: ["NA", "NULL", ""]
Cross-DC Links¶
Interactive filtering between data collections at runtime:
links:
- source_dc_id: "metadata" # Filter from this DC
source_column: "sample_id" # Filter by this column
target_dc_id: "multiqc_report" # Update this DC
target_type: "multiqc" # Target type: table or multiqc
link_config:
resolver: "sample_mapping" # Maps canonical IDs to MultiQC variants
See Cross-DC Filtering for details.
Custom Workflows¶
Support for various workflow engines:
engine:
name: "nextflow" # or "snakemake", "python", "cwl", "galaxy"
version: "24.10.3" # Version for reproducibility
catalog:
name: "nf-core" # Workflow catalog
url: "https://nf-co.re/rnaseq"
🚀 Best Practices¶
Project Organization¶
- Naming Convention - Use descriptive, consistent names
- Documentation - Include comprehensive descriptions
- Version Control - Track configuration changes
- Testing - Validate configurations before deployment
Data Management¶
- File Organization - Maintain consistent directory structures
- Metadata - Include comprehensive column descriptions
- Validation - Use schema validation for data quality
- Backup - Implement regular backup strategies
Performance Optimization¶
- Column Selection - Use
keep_columnsto reduce memory usage - File Formats - Prefer Parquet over CSV for large datasets
- Partitioning - Organize data by frequently queried columns
- Indexing - Create appropriate indexes for query patterns
Collaboration¶
- Permission Management - Set appropriate access levels
- Documentation - Maintain clear project documentation
- Communication - Use descriptive commit messages for changes
- Standardization - Establish team conventions
🔍 Troubleshooting¶
Common Issues¶
Problem: YAML validation fails
Solutions:
Problem: Files not found during scanning
Solutions: - Verify file paths and permissions - Test regex patterns with sample files - Check environment variable resolution - Use dry-run mode for testing
Problem: Access denied to project resources
Solutions: - Verify user roles and permissions - Check project visibility settings - Confirm authentication status - Contact project owners for access
Problem: Slow dashboard loading
Solutions: - Use column selection to reduce data size - Use links for runtime filtering instead of pre-computed joins - Consider data partitioning - Review query patterns
Debugging Commands¶
# Verbose execution with detailed logging
depictio-cli run --project-config-path ./config.yaml \
--verbose --verbose-level DEBUG
# Dry run to preview operations
depictio-cli run --project-config-path ./config.yaml --dry-run
# Step-by-step execution for debugging
depictio-cli config check-server-accessibility
depictio-cli config validate-project-config --project-config-path ./config.yaml
depictio-cli data scan --project-config-path ./config.yaml
📚 Additional Resources¶
- CLI Reference - Complete CLI documentation
- YAML Examples - Comprehensive configuration examples
- Configuration Reference - Complete YAML reference
- Dashboard Creation - Building interactive dashboards
- API Documentation - Programmatic project management
Projects form the foundation of data organization in Depictio. Choose the right project type for your workflow to unlock the full power of interactive data exploration and collaboration.