nf-core/viralrecon¶
nf-core pipeline · nf-co.re/viralrecon
The viralrecon template covers the main outputs of a standard nf-core/viralrecon run. The pipeline itself supports any viral genome configured in nf-core's reference-genomes config; the bundled depictio template was validated against SARS-CoV-2 / ARTIC amplicon data but the recipe / dashboard structure carries over to other viruses with the same iVar variant-calling + Pangolin / Nextclade lineage layout.
- MultiQC quality control — FastQC, Cutadapt, samtools/picard alignment metrics
- Variant calling — iVar variants with gene, effect, and allele-frequency annotations
- Lineage assignment — Pangolin lineages with conflict and QC scores
- Clade assignment — Nextclade clades with substitution counts
- Coverage analysis — Mosdepth amplicon coverage, genome coverage, and amplicon heatmap
- Cross-sample landscape — variant landscape and lineage analysis dashboards
Quick start¶
Unlike the ampliseq template, viralrecon needs no extra template variables —
just point --data-root at the pipeline's output directory. The template
expects nf-core/viralrecon's standard layout:
viralrecon_results/
├── multiqc/
│ ├── multiqc_data/
│ │ └── multiqc.parquet
│ └── summary_variants_metrics_mqc.csv
└── variants/
└── ivar/
├── consensus/
│ └── bcftools/
│ ├── pangolin/*.pangolin.csv
│ └── nextclade/*.csv
├── variants_long_table.csv
└── *.mosdepth.{coverage,heatmap}.tsv
--variant_caller ivar is required
The viralrecon template's recipes hardcode paths under variants/ivar/
(see variants_long.py, pangolin_lineages.py, nextclade_results.py).
Running nf-core/viralrecon with the alternative --variant_caller bcftools
produces a different output layout that the template won't match.
Aggregated data collections
All eight viralrecon DCs use metatype: "Aggregated". They are built
by recipes that fan multiple per-sample files into a single delta
table via glob_pattern. See Recipes
for the underlying mechanism.
Template variables¶
| Variable | Required | Auto | Description |
|---|---|---|---|
DATA_ROOT |
— | Pipeline output root (set via --data-root) |
The viralrecon template's recipes use glob_pattern to discover
per-sample files relative to DATA_ROOT, so no samplesheet path needs to
be passed.
Test data¶
A small test fixture is available for local development without re-running
the full pipeline. The repository ships
download_test_data.sh
which fetches a real viralrecon run from nf-core's AWS megatest bucket:
bash depictio/projects/nf-core/viralrecon/3.0.0/download_test_data.sh \
--target /tmp/viralrecon_test
This pulls a published run from
s3://nf-core-awsmegatests/viralrecon/results-395079f1d24dce731ac22e03d7a5e71f110103fc/
and validates that all expected file patterns are present.
Once the download finishes, run depictio against it:
--variant_caller ivar is required
The viralrecon template's recipes hardcode paths under variants/ivar/.
Running nf-core/viralrecon with --variant_caller bcftools produces a
different output layout that the template won't match.
Alternative: run nf-core/viralrecon locally
The script can also re-run nf-core/viralrecon end-to-end if you'd rather regenerate the fixture from scratch:
Data collections¶
| Data Collection | Type | Recipe | Key columns | Description |
|---|---|---|---|---|
multiqc_data |
MultiQC | — | (MultiQC native fields) | Native MultiQC parquet — FastQC, Cutadapt, alignment metrics |
summary_metrics |
Table | summary_metrics.py |
sample, num_reads_mapped, pct_genome_covered_10x, num_variants_total, lineage |
Per-sample alignment, coverage, and variant counts |
variants_long |
Table | variants_long.py |
sample, CHROM, POS, REF, ALT, FILTER, DP, AF |
Per-variant calls with gene, effect, allele frequency |
pangolin_lineages |
Table | pangolin_lineages.py |
sample, lineage, conflict, scorpio_call, qc_status |
Per-sample Pangolin lineage with conflict / QC scores |
nextclade_results |
Table | nextclade_results.py |
sample, clade, Nextclade_pango, totalSubstitutions, totalDeletions |
Per-sample Nextclade clade with substitution counts |
mosdepth_amplicon_coverage |
Table | — | sample, amplicon, coverage |
Per-amplicon Mosdepth coverage |
mosdepth_genome_coverage |
Table | — | sample, chrom, start, end, coverage |
Genome-window Mosdepth coverage |
mosdepth_amplicon_heatmap |
Table | — | sample, amplicon, coverage |
Mosdepth amplicon coverage heatmap |
All DCs use metatype: "Aggregated". The three Mosdepth DCs are native
table scans (no recipe); the others are Polars recipes that fan per-sample
files via glob_pattern.
Cross-DC links are wired so a sample selection in any tab filters every
linked DC across the dashboard. See Cross-DC links below.
Dashboard tabs¶
The viralrecon template ships a five-tab dashboard (MultiQC parent +
four child tabs). Each tab targets a different analytical question;
filters propagate across tabs via cross-DC links on the
summary_metrics.sample column.
Pipeline-level quality control powered by MultiQC.
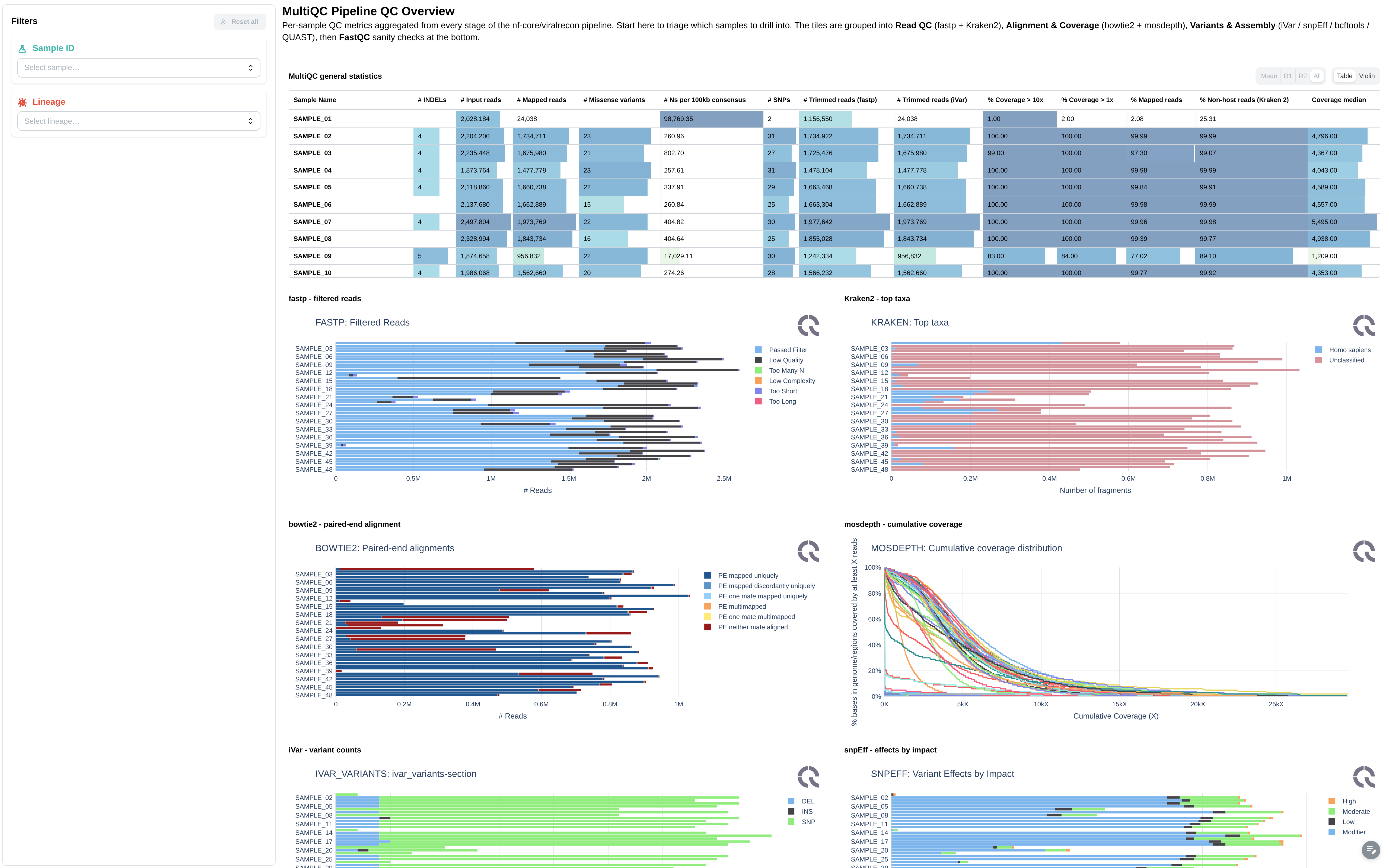
Filters: Sample ID, Lineage.
Components: 11 MultiQC plots covering raw read counts, trimming statistics, alignment rate, duplication rate, samtools/picard metrics, and variant counts.
Per-sample and per-amplicon coverage view.
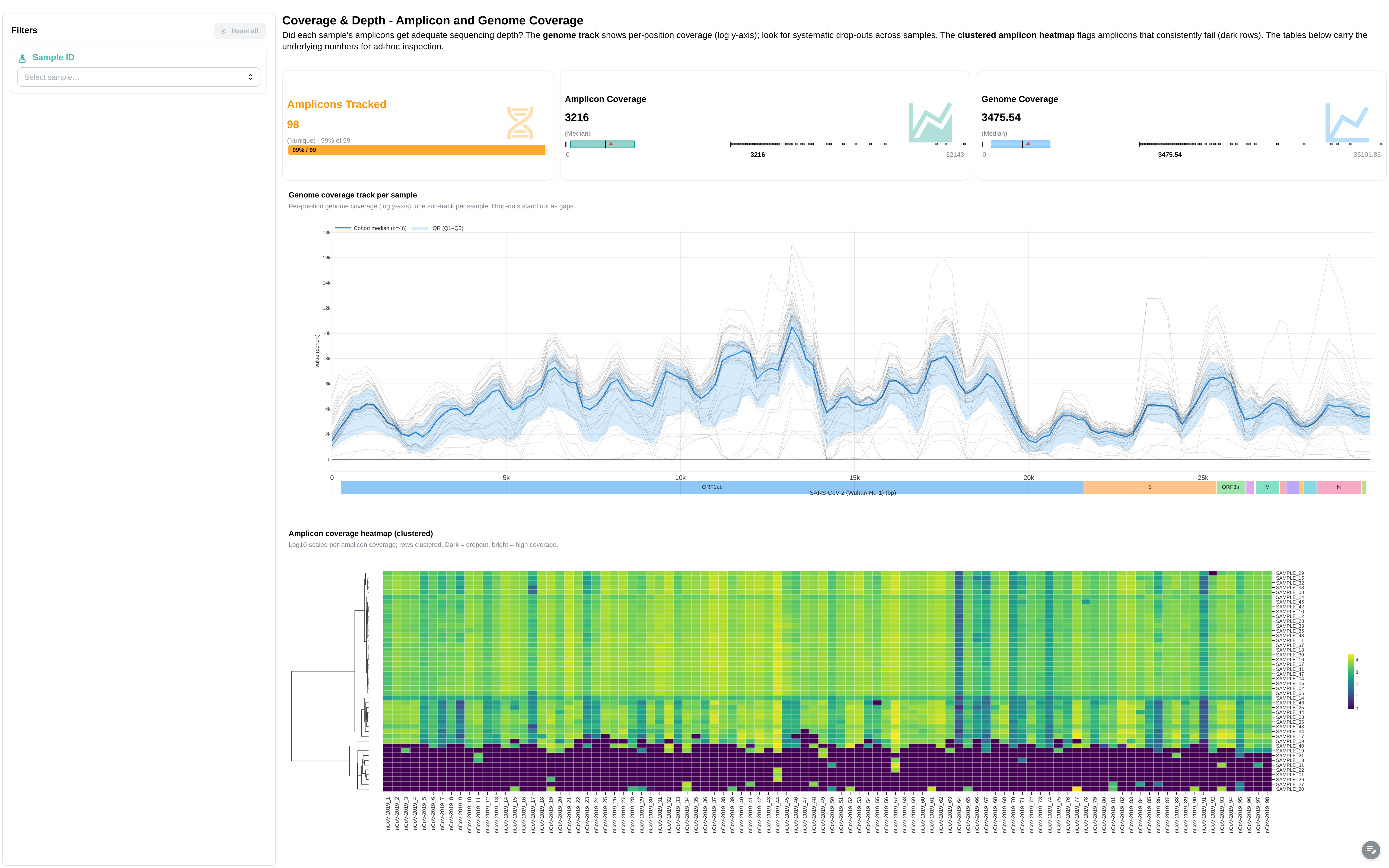
Filters: Sample ID.
Components:
- 4 summary cards: Total Samples, Amplicons Tracked, Amplicon Coverage, Genome Coverage
- Genome Coverage per Sample (line chart)
- Amplicon Coverage Heatmap
- Amplicon Coverage Data table
- Genome Coverage Data table
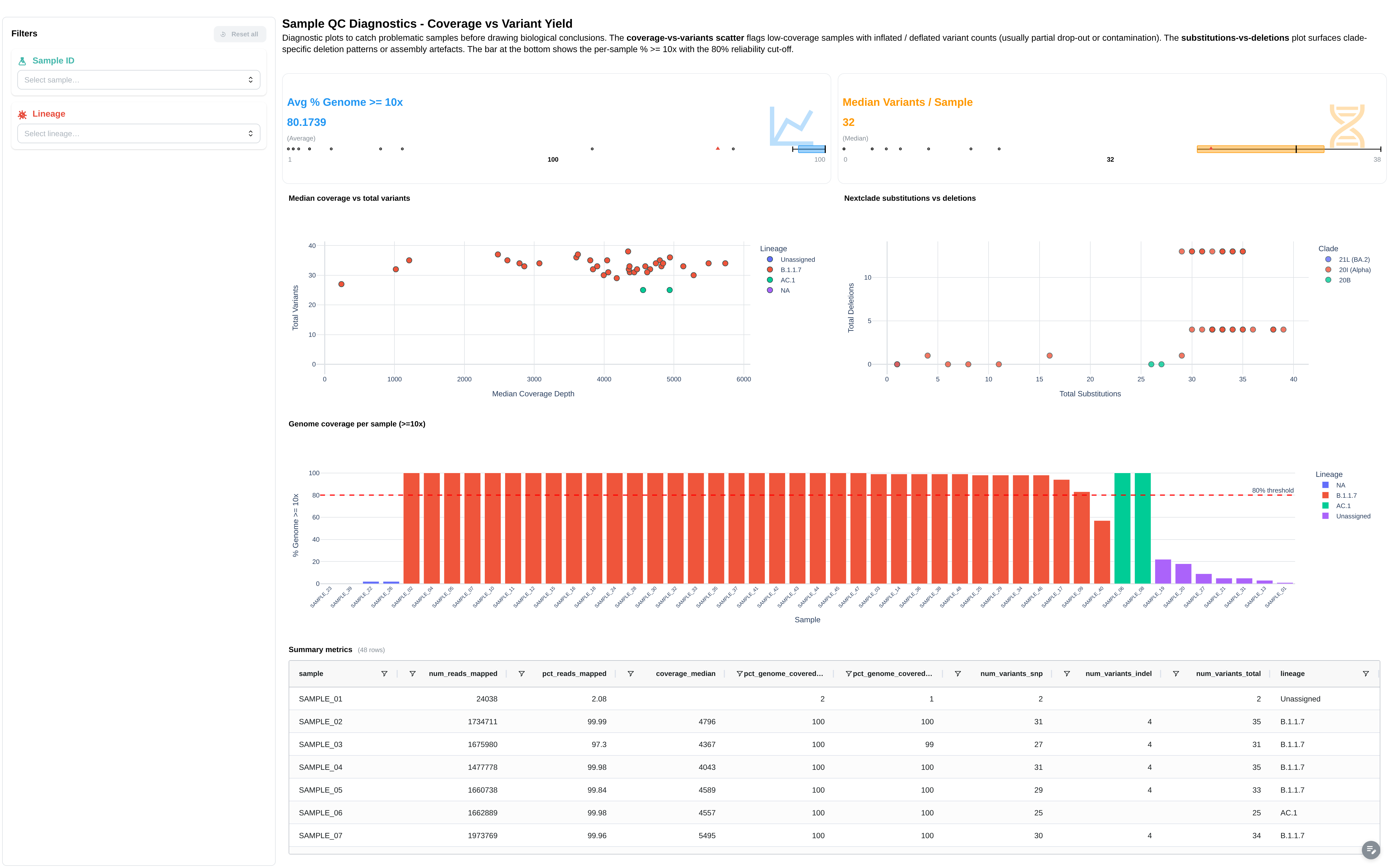
Pangolin lineage and Nextclade clade assignment, plus a Sankey funnel from QC status → lineage → clade.
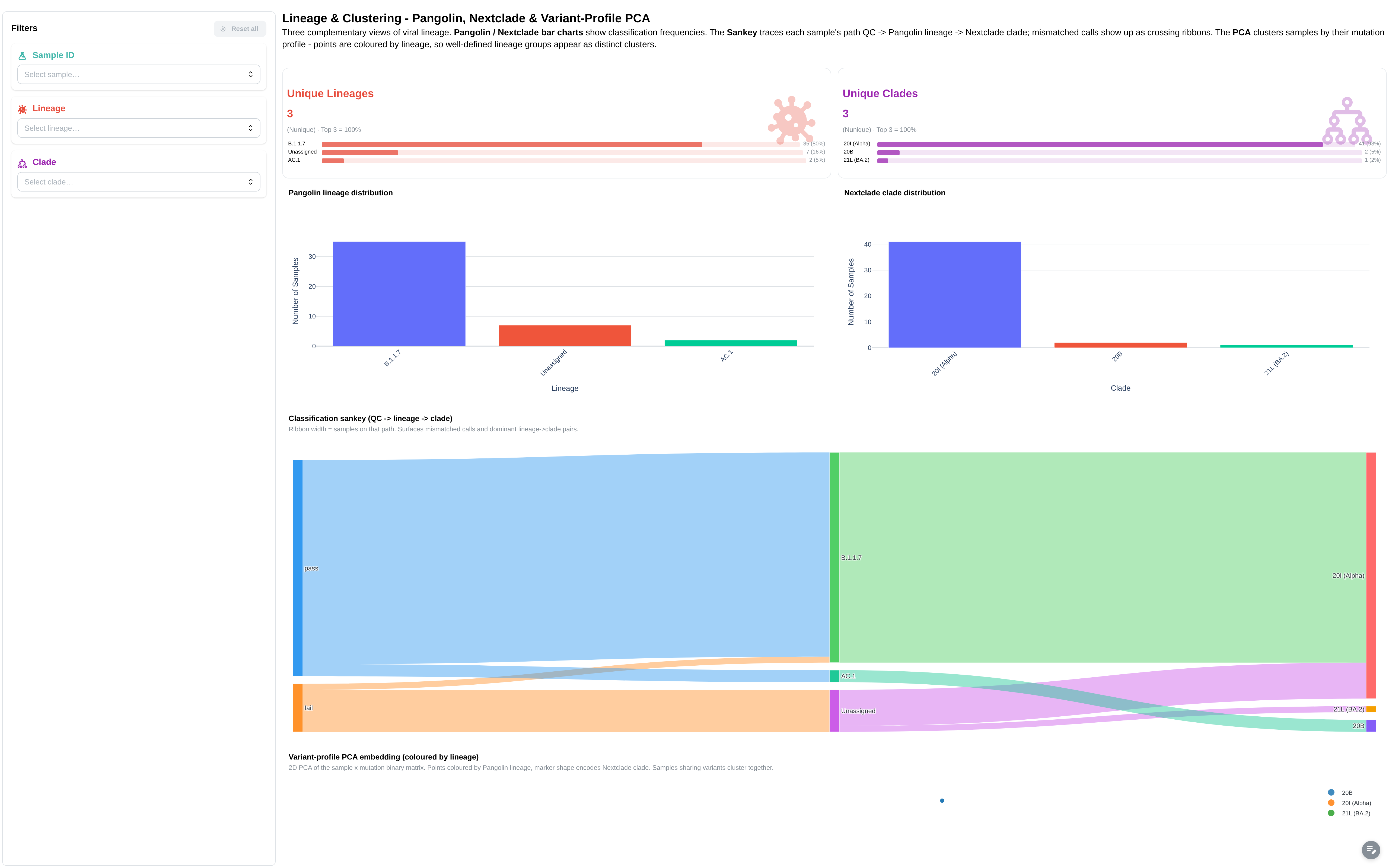
Filters: Sample ID, Lineage, Clade, QC Status.
Components:
- 4 summary cards: Total Samples, Unique Lineages, Unique Clades, Avg Genome Coverage (10x)
- 6 figures: Pangolin Lineage Distribution, Nextclade QC Status Overview, Nextclade Clade Distribution, Coverage vs Total Variants by Lineage, Genome Coverage per Sample (>= 10x Depth), Nextclade — Substitutions vs Deletions by Clade
- Sankey funnel: qc_status → lineage → clade (canonical sankey)
- 3 tables: Pangolin Lineage Assignments, Nextclade Clade Assignments, Summary Metrics
Variant calls and functional effects, with manhattan-style genome landscape and oncoplot of high-impact mutations.
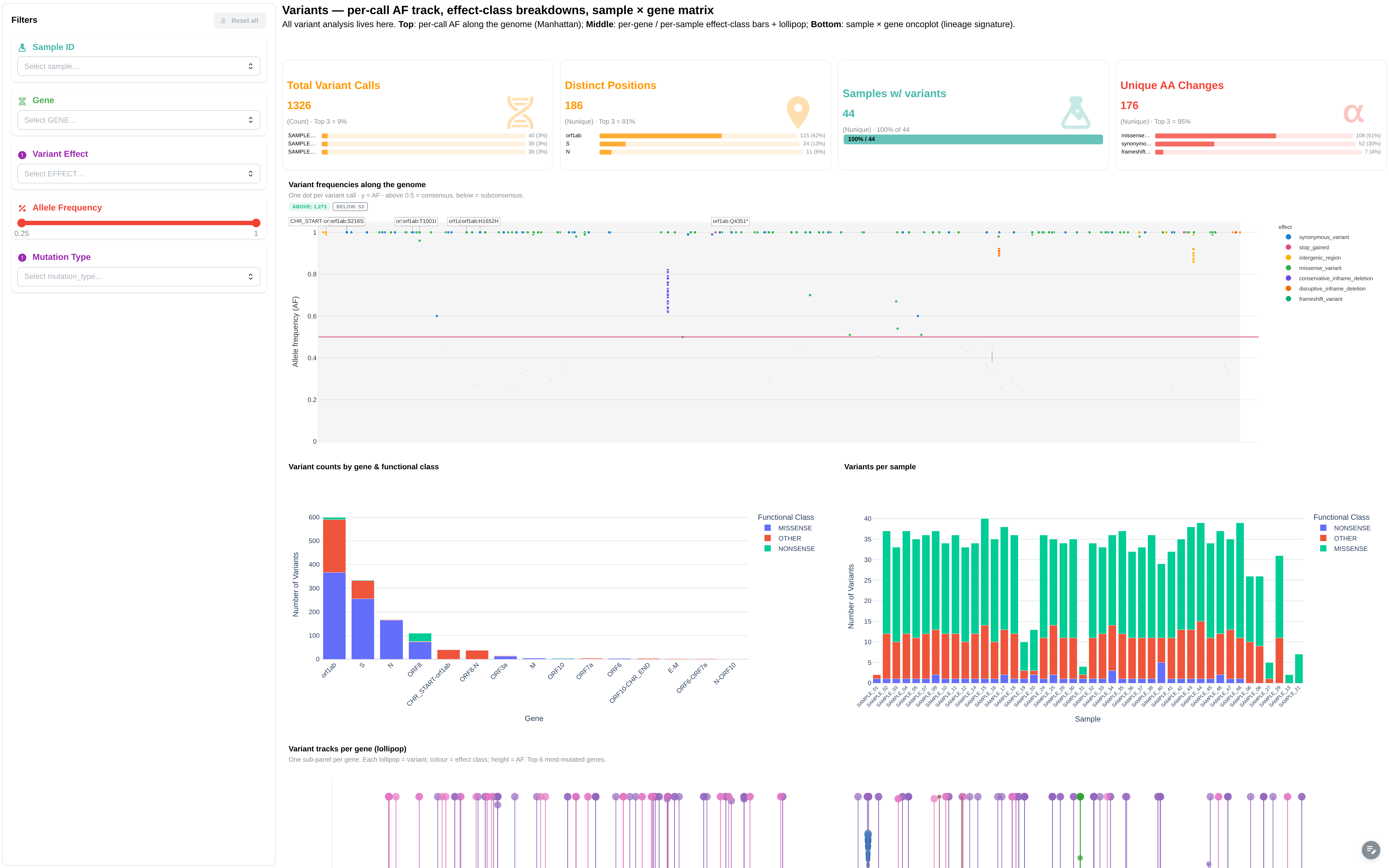
Filters: Sample ID, Gene, Variant Effect, Functional Class, Allele Frequency (range), Read Depth (range).
Components:
- 4 summary cards: Total Variants, Unique Genes, Mean Allele Freq, Unique AA Changes
- Manhattan plot: chr × pos × score (canonical manhattan)
- Lollipop: per-gene variants (canonical lollipop)
- Oncoplot: sample × gene × mutation_type (canonical oncoplot)
- 5 figures: Allele Frequency vs Genome Position, Variant Count by Gene and Functional Class, Variant Effect Distribution, Variant Functional Class Distribution, Variant Count per Sample
- 1 table: Variants Long Table
Per-sample QC scorecard combining alignment, coverage, variant counts and lineage / clade assignment in one place.
Filters: Sample ID, Lineage, QC Status.
Components:
- Summary cards: total samples, samples passing QC, mean coverage, mean variants per sample
- Sample × metric heatmap (canonical complex heatmap)
- Summary metrics table
Recipes¶
The viralrecon template ships four Polars recipes under
depictio/recipes/nf-core/viralrecon/. Three use glob_pattern to fan
per-sample files into a single delta table; one reads a single MultiQC-
generated CSV.
depictio/recipes/nf-core/viralrecon/summary_metrics.py
Source: multiqc/summary_variants_metrics_mqc.csv (single file
produced by viralrecon's MultiQC step).
Output schema:
| Column | Type |
|---|---|
sample |
Utf8 |
num_reads_mapped |
Float64 |
pct_reads_mapped |
Float64 |
coverage_median |
Float64 |
pct_genome_covered_1x, _10x |
Float64 |
num_variants_snp, _indel, _total |
Float64 |
lineage |
Utf8 |
depictio/recipes/nf-core/viralrecon/variants_long.py
Source: variants/ivar/variants_long_table.csv (single ivar
long-format variant table covering all samples).
Output schema:
| Column | Type | Notes |
|---|---|---|
sample |
Utf8 |
Sample identifier |
CHROM |
Utf8 |
Reference contig |
POS |
Int64 |
1-based position |
REF, ALT |
Utf8 |
Alleles |
FILTER |
Utf8 |
ivar filter status |
DP |
Int64 |
Total depth |
REF_DP, ALT_DP |
Int64 |
Per-allele depth |
AF |
Float64 |
Allele frequency |
| gene / effect / function annotations |
depictio/recipes/nf-core/viralrecon/pangolin_lineages.py
Source (glob):
variants/ivar/consensus/bcftools/pangolin/*.pangolin.csv
— one file per sample.
Output schema:
| Column | Type |
|---|---|
sample |
Utf8 |
lineage |
Utf8 |
conflict, ambiguity_score |
Float64 |
scorpio_call |
Utf8 |
scorpio_support |
Float64 |
pangolin_version |
Utf8 |
qc_status |
Utf8 |
depictio/recipes/nf-core/viralrecon/nextclade_results.py
Source (glob):
variants/ivar/consensus/bcftools/nextclade/*.csv
— one file per sample, semicolon-separated (recipe sets
read_kwargs={"separator": ";"}).
Output schema:
| Column | Type |
|---|---|
sample |
Utf8 |
clade |
Utf8 |
Nextclade_pango |
Utf8 |
totalSubstitutions, totalDeletions, totalInsertions |
Int64 |
totalFrameShifts, totalMissing, totalNonACGTNs |
Int64 |
QC fields (qc.overallStatus, etc.) |
Utf8 |
Cross-DC links¶
The viralrecon template wires seven cross-DC links from
summary_metrics.sample to every other data collection — selecting a
sample propagates the filter across:
multiqc_data(resolver:sample_mapping)variants_longpangolin_lineagesnextclade_resultsmosdepth_amplicon_coveragemosdepth_genome_coveragemosdepth_amplicon_heatmap
This star-topology means summary_metrics is the canonical "sample
roster" for the dashboard — adding a new DC just requires another link
from summary_metrics.sample to wire it into the existing filter graph.